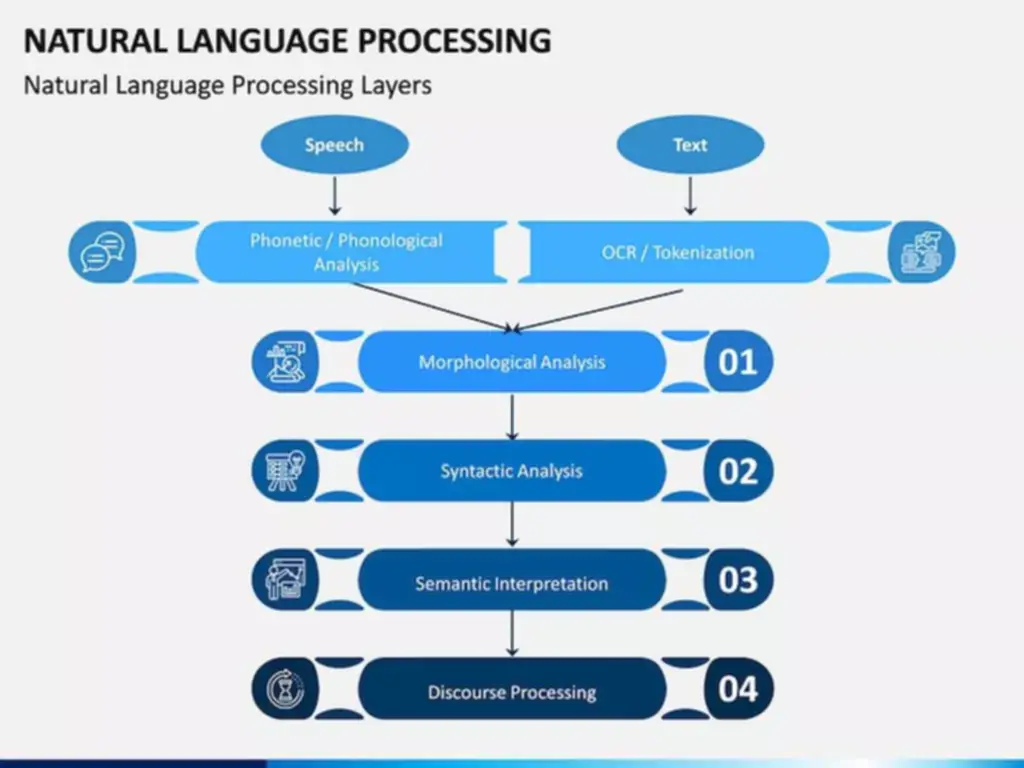
The first part chooses whether or not the information coming from the previous timestamp is to be remembered or is irrelevant and could be forgotten. In the second part, the cell tries to study new info from the input to this cell. At last, in the third part, the cell passes the up to date info from the current timestamp to the following timestamp.
What Are Recurrent Neural Networks?
A scalable methodology for encoding community connectivity was introduced, making it extra efficient in evolving deep neural networks for federated studying settings. The experiment outcomes on multi-layer perceptions and CNN showed that the proposed technique successfully decreased communication demands and enhanced learning performance in comparison with standard totally linked neural networks. Backpropagation via time (BPTT) is the first algorithm used for training LSTM neural networks on time series knowledge.
- Also, the performance of federated learning (FL) strategies was evaluated to explore privacy-preserving and scalable options for intrusion detection in decentralized IoT environments.
- This can be added to the cell state, nevertheless, the reality that he informed all this over the cellphone is a less essential truth and can be ignored.
- Attention mechanisms enable the community to concentrate on related parts of the enter sequence, improving performance on tasks like machine translation.
- Parra et al.52 introduced a method that synergizes Flower, an FL platform, with Optuna for enhanced hyperparameter optimization (HPO).
- A long for-loop in the ahead methodology will resultin an especially lengthy JIT compilation time for the primary run.
The input gate is responsible for the addition of information to the cell state. This addition of knowledge is mainly three-step process as seen from the diagram above. The information that’s not required for the LSTM to grasp things or the data that is of less significance is removed through multiplication of a filter. As quickly as the first full stop after “person” is encountered, the neglect gate realizes that there could also be a change of context within the next sentence. As a result of this, the subject of the sentence is forgotten and the place for the subject is vacated.
Evaluating And Validating Models
It is a special kind of Recurrent Neural Community which is able to dealing with the vanishing gradient drawback confronted by RNN. LSTM was designed by Hochreiter and Schmidhuber that resolves the issue attributable to conventional rnns and machine learning algorithms. Furthermore, the results obtained from the datasets would greatly benefit http://www.rusnature.info/geo/03_8.htm the scientific community thinking about IDSs for IoT/IIoT purposes.

Utilized Machine Learning Engineer skilled in Computer Vision/Deep Learning Pipeline Improvement, creating machine studying fashions, retraining methods, and remodeling knowledge science prototypes to production-grade options. Consistently optimizes and improves real-time methods by evaluating methods and testing real-world situations. LSTM networks are a special kind of RNN designed to keep away from the long-term dependency downside.
In standard RNNs, this repeating module will have a quite simple construction, similar to a single tanh layer. This article talks concerning the issues of typical RNNs, particularly, the vanishing and exploding gradients, and supplies a handy answer to these problems within the type of Lengthy Quick Time Period Memory (LSTM). Long Short-Term Memory is a sophisticated version of recurrent neural network (RNN) architecture that was designed to model chronological sequences and their long-range dependencies more precisely than typical RNNs. This superior efficiency is attributed to LSTM-JSO’s capability to capture long-range dependencies in sequential data, which is essential http://www.rusnature.info/reg/09_12.htm?_sm_byp=iVVF5jDP4nNHS584 for identifying time-dependent assault patterns. In Contrast To CNNs, which excel at spatial feature extraction however wrestle with time-series data, LSTM is specifically designed for sequential data processing. Furthermore, LSTM-JSO presents a computationally efficient alternative to Transformer models, that are resource-intensive because of their self-attention mechanisms.
Together With knowledge sets spanning numerous domains, from social media content to medical data, ensures that the proposed fashions are rigorously examined throughout diverse scenarios. This broad analysis framework is crucial for demonstrating the models’ scalability and robustness, affirming their ability to carry out effectively in real-world purposes throughout varied fields. Determine 10 evaluates the models on the Thermostat dataset, evaluating their performance throughout precision, recall, F1-score, and accuracy. The LSTM-JSO consistently achieves the highest metrics, confirming its robustness and scalability in detecting intrusions in good residence IoT techniques.
Now the new information that needed to be handed to the cell state is a operate of a hidden state on the previous timestamp t-1 and input x at timestamp t. Due to the tanh function, the worth of recent info shall be between -1 and 1. If the worth of Nt is negative, the knowledge is subtracted from the cell state, and if the value is constructive, the knowledge is added to the cell state at the present timestamp.
The enter sequence of the mannequin could be the sentence within the supply language (e.g. English), and the output sequence could be the sentence in the target language (e.g. French). The tanh activation perform is used as a result of its values lie within the vary of -1,1. This capability to supply negative values is crucial in reducing the affect of a component in the cell state. Key steps in knowledge preparation include identifying and treating outliers, normalizing steady variables, and encoding categorical variables. Feature engineering, such as creating interplay terms or polynomial features, can also enhance the mannequin’s efficiency by capturing complicated relationships within the information.
The LSTM-JSO achieves the very best metrics, demonstrating its precision and recall in detecting malicious actions in good equipment datasets. LSTMs are a very promising answer to sequence and time sequence related issues. Nevertheless, the one drawback that I discover about them, is the issue in training them.
To mannequin with a neural community, it is suggested to extract the NumPy array from the dataframe and convert integer values to floating point values. In the above architecture, the output gate is the ultimate step in an LSTM cell, and this is solely one a part of the entire course of. Earlier Than the LSTM community can produce the desired predictions, there are a couple of extra issues to contemplate.
The bidirectional LSTM comprises two LSTM layers, one processing the enter sequence within the forward path and the other in the backward course. This allows the community to entry information from past and future time steps simultaneously. Lengthy Short-Term Reminiscence Networks or LSTM in deep learning, is a sequential neural community that permits information to persist.
We multiply the previous state by ft, disregarding the information we had beforehand chosen to disregard. This represents the up to date http://www.rusnature.info/geo/02_3.htm candidate values, adjusted for the quantity that we chose to update every state value. Statistical significance was assessed using the Wilcoxon rank-sum take a look at, confirming that LSTM-JSO considerably outperforms different models, with p-values under 0.05, further validating its robustness.
Najnowsze komentarze